
Code
<Axes: >
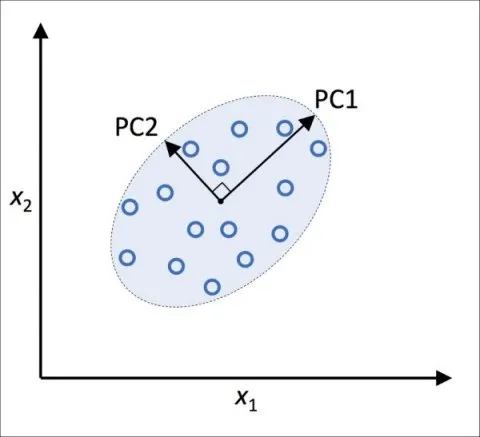
Principal Component Analysis
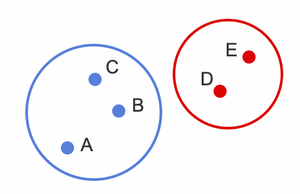
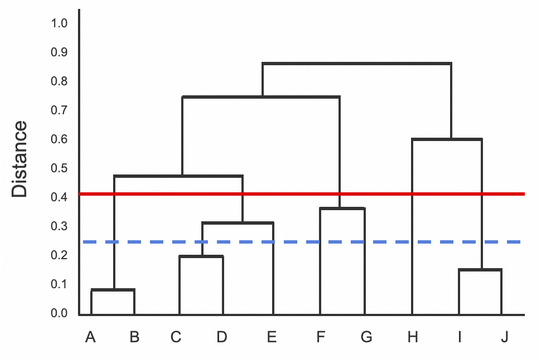
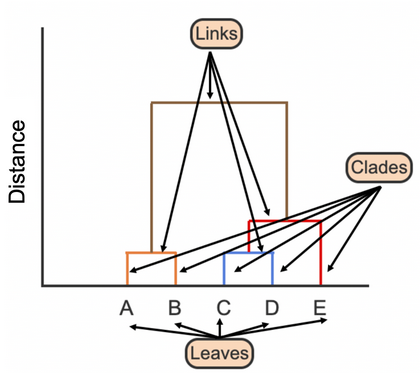
Which two samples should be used to determine similarity using the Single linkage? Complete Linkage?
Which two samples should be used to determine similarity using the Single linkage? Complete Linkage?
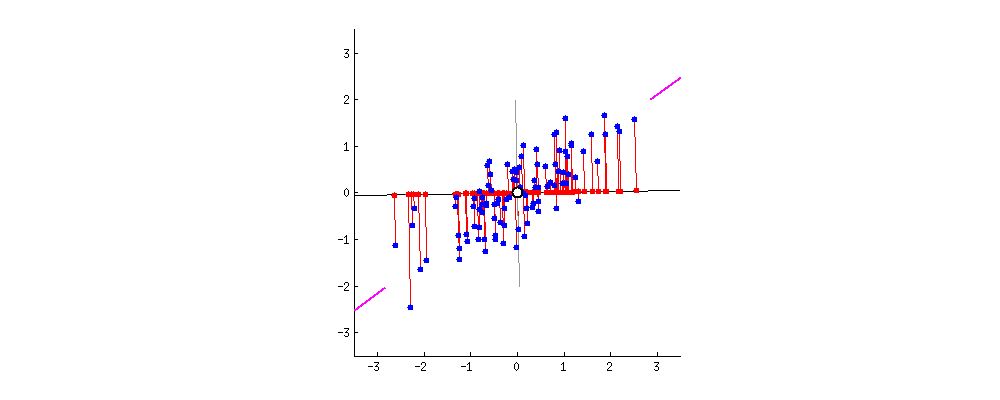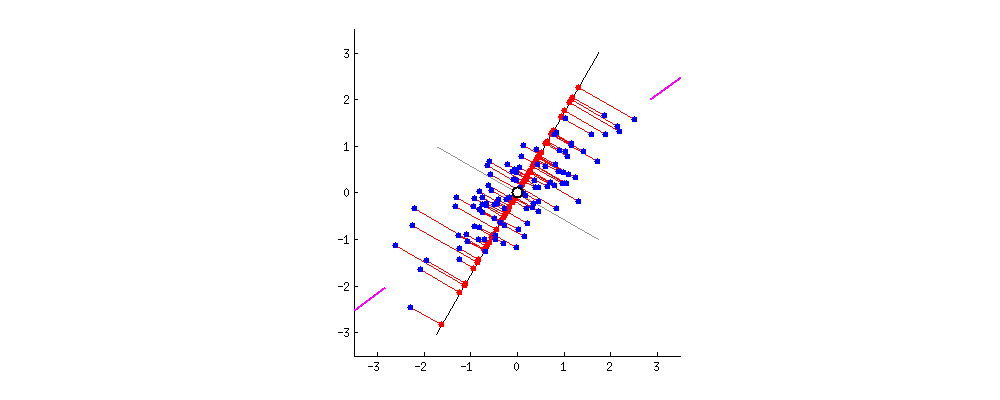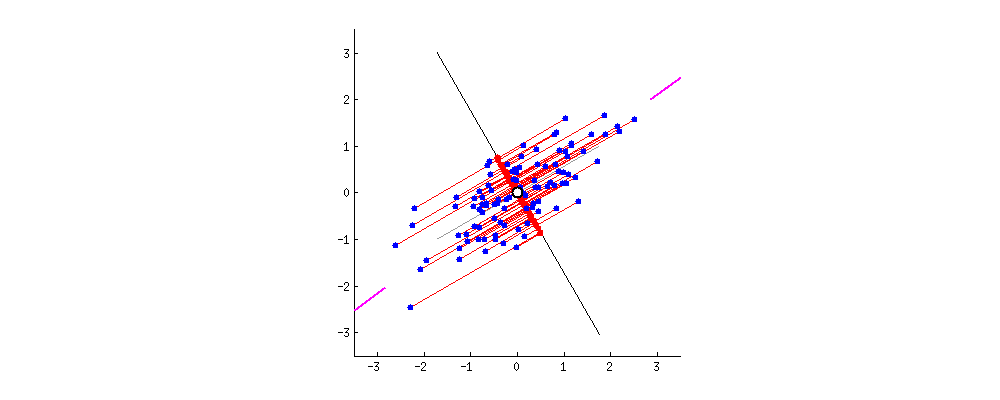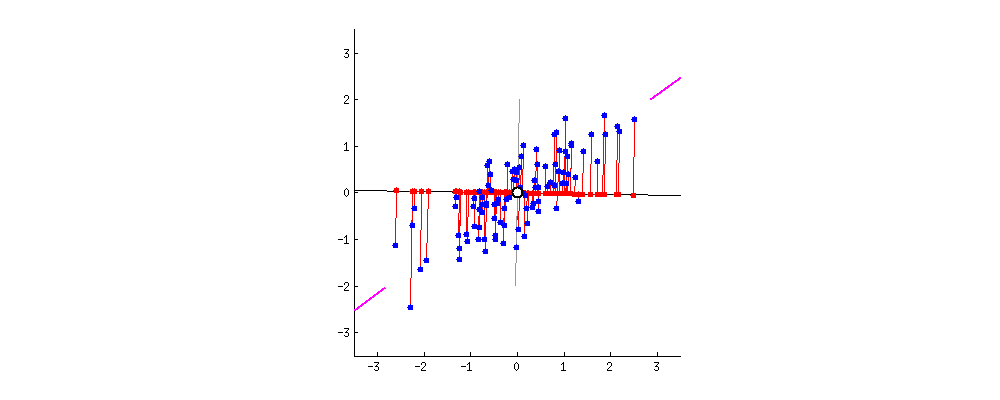
Find me a vector or axis that when you project the data to it maximizes the variance
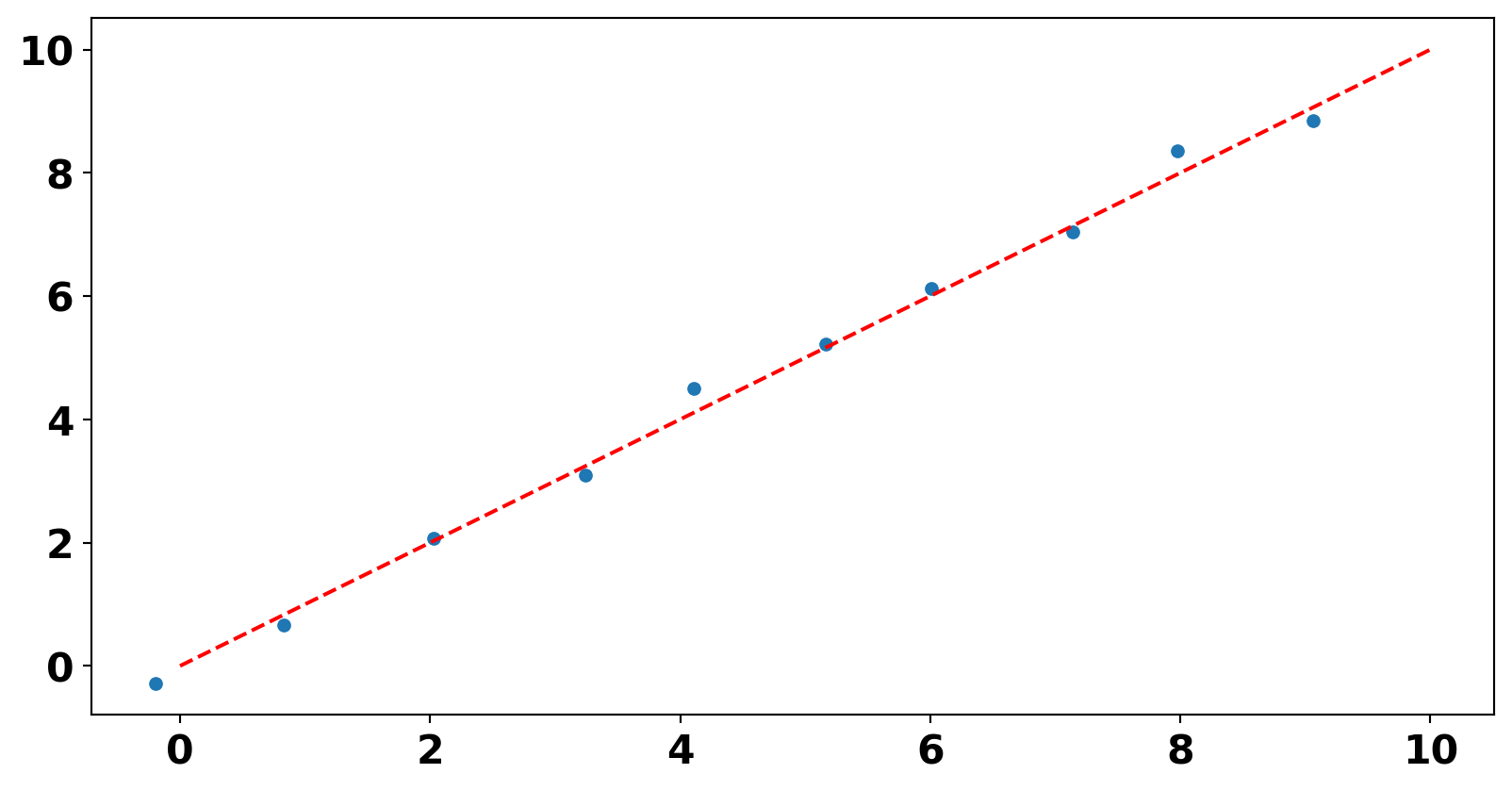
x = np.arange(0, 10) + np.random.randn(10) * 0.1
y = np.arange(0, 10) + np.random.randn(10) * 0.1
z = x * 1 + y * 2 + np.random.randn(10) * 1
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
X = np.column_stack([x, y, z])
ax.scatter(x, y, z, marker='o')
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')Text(0.5, 0, 'Z Label')
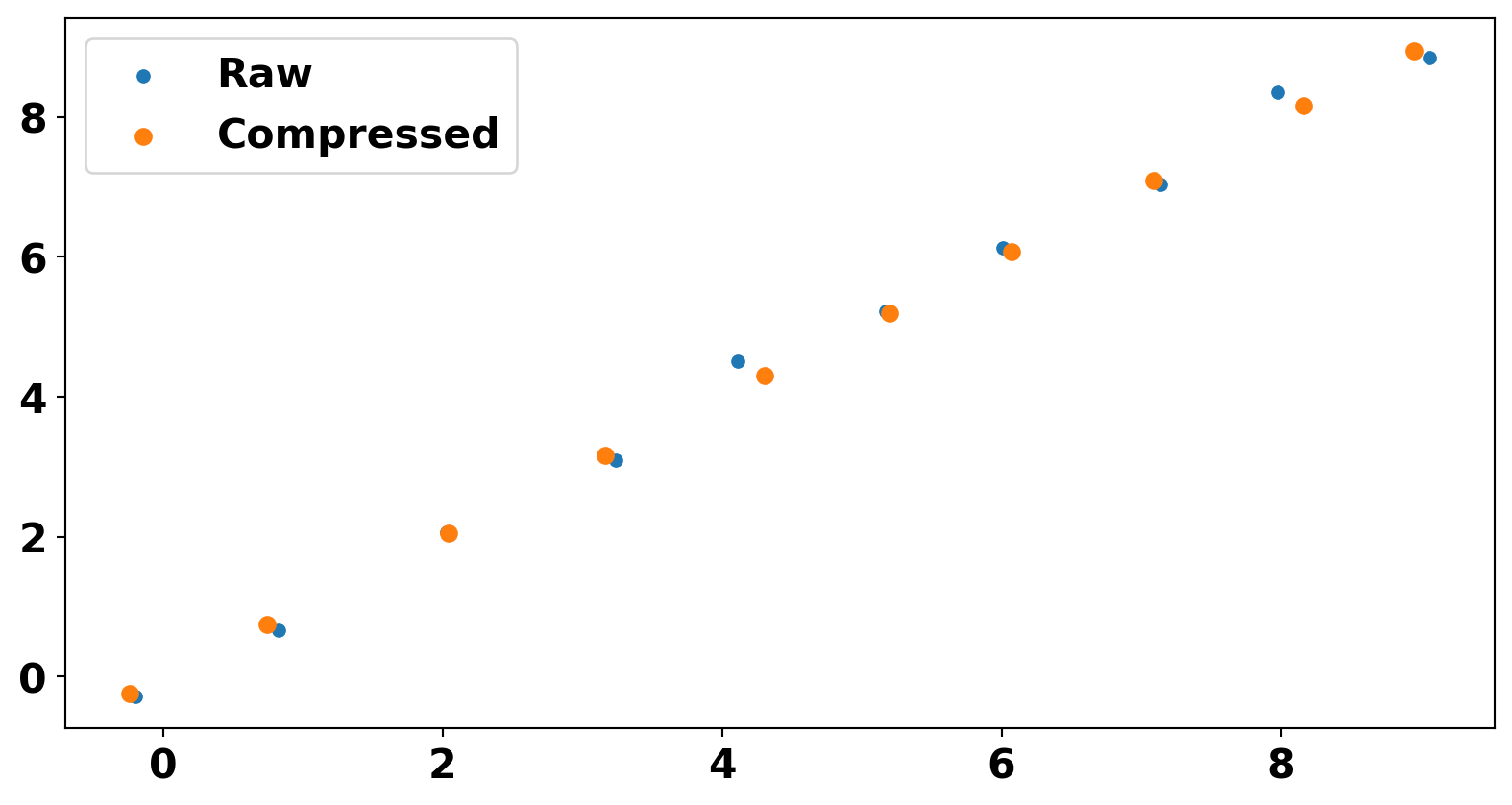
from sklearn.decomposition import PCA
pca = PCA(n_components=1)
# fit and transform data
X_pca = pca.fit_transform(X)
print(X_pca.shape)
X_comp = pca.inverse_transform(X_pca)
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
ax.scatter(x, y, z, marker='o', label='Raw')
ax.scatter(X_comp[:, 0], X_comp[:, 1], X_comp[:, 2], marker='x', label='compressed')
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')(10, 1)Text(0.5, 0, 'Z Label')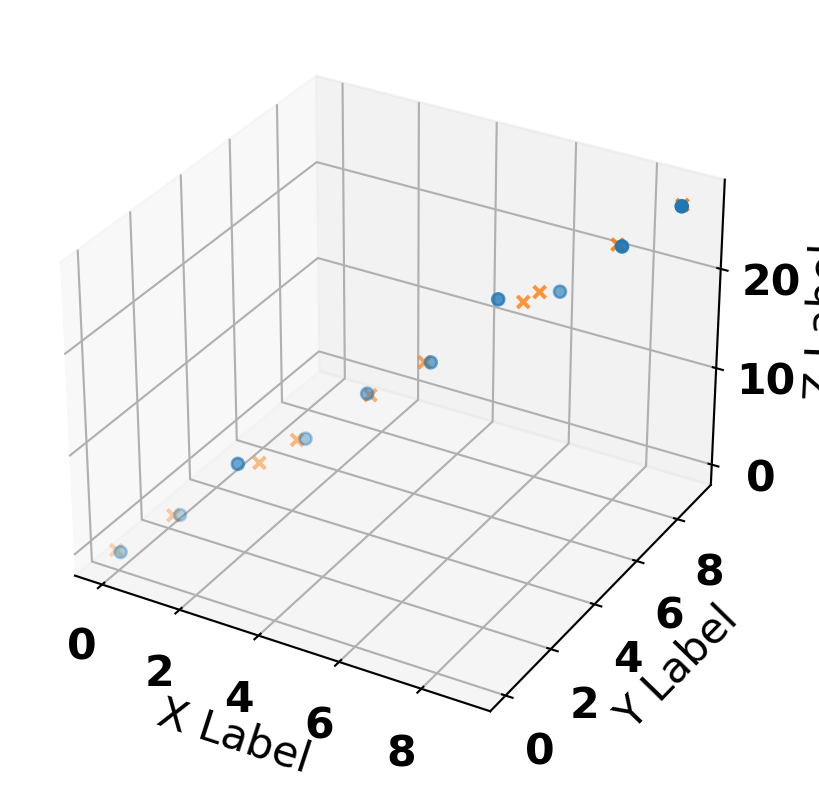
[[2.6 -0.0]
[0.2 2.3]
[-2.6 -2.7]
[-2.5 -0.5]
[1.7 0.9]
[-2.8 -0.4]
[-2.8 -2.0]
[1.4 -0.0]
[-2.5 0.1]
[-2.3 0.4]
[1.1 2.4]
[-2.3 1.1]
[-2.5 -0.6]
[0.2 1.1]
[2.5 -1.1]
[-0.7 2.8]
[2.5 0.2]
[-0.6 0.7]
[0.5 -0.4]
[3.6 -1.4]
[1.6 1.5]
[2.5 0.1]
[-3.6 -0.9]
[-1.6 -2.4]
[1.5 1.4]
[0.0 2.0]
[-0.2 2.8]
[-2.4 -2.5]
[-3.1 0.3]
[3.3 -0.4]
[-3.5 -1.8]
[-0.5 2.6]
[-0.6 2.0]
[-1.2 0.8]
[1.0 1.4]
[2.0 1.6]
[2.8 -1.9]
[2.1 -1.3]
[0.8 2.0]
[3.5 -1.4]
[-3.8 -0.1]
[1.7 0.5]
[-3.4 -0.9]
[3.1 -0.8]
[2.3 -1.7]
[1.3 0.9]
[3.6 -1.8]
[0.9 2.3]
[0.5 2.0]
[3.8 -2.9]
[-2.4 -2.2]
[-1.6 1.4]
[2.5 -1.3]
[-0.7 0.2]
[-0.8 2.4]
[0.8 1.5]
[-1.3 -0.0]
[2.2 -0.9]
[-3.9 -0.5]
[-1.8 -1.3]
[4.4 -2.3]
[3.3 -1.4]
[-1.5 1.9]
[-2.7 -2.2]
[2.8 -1.4]
[1.9 -0.7]
[-0.5 2.2]
[-0.1 1.2]
[2.0 -0.2]
[2.2 -1.3]
[0.8 -0.3]
[-3.3 -2.2]
[0.9 0.8]
[2.3 0.1]
[0.8 1.4]
[-2.3 -0.6]
[3.1 -1.3]
[-1.7 1.8]
[-2.9 -0.2]
[-2.7 -0.3]
[1.9 -1.6]
[1.6 0.6]
[-2.0 -0.3]
[2.3 -1.9]
[-2.3 -0.2]
[-0.4 2.0]
[1.4 -0.7]
[2.2 -0.7]
[-0.4 1.9]
[2.8 -1.5]
[-2.8 -1.9]
[-1.6 1.4]
[-3.4 -1.1]
[1.7 -0.1]
[-2.9 -0.4]
[-2.3 -2.2]
[-3.5 -1.3]
[2.3 -0.3]
[1.5 2.1]
[-0.4 2.4]
[0.4 1.1]
[0.5 3.9]
[-2.7 -1.6]
[-3.2 -2.7]
[-0.6 1.0]
[-1.4 1.5]
[0.9 -0.7]
[1.1 1.3]
[-2.8 -1.3]
[-2.4 -2.4]
[2.5 -1.9]
[3.2 -1.8]
[-2.7 -0.2]
[-1.1 1.8]
[-1.5 1.0]
[-0.5 2.5]
[1.4 -0.7]
[1.1 -0.2]
[2.8 -1.0]
[-0.5 2.6]
[0.3 2.3]
[-0.1 2.0]
[2.9 -0.8]
[-2.4 -2.2]]from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(C=1e5)
model.fit(X_train_pca, y_train)
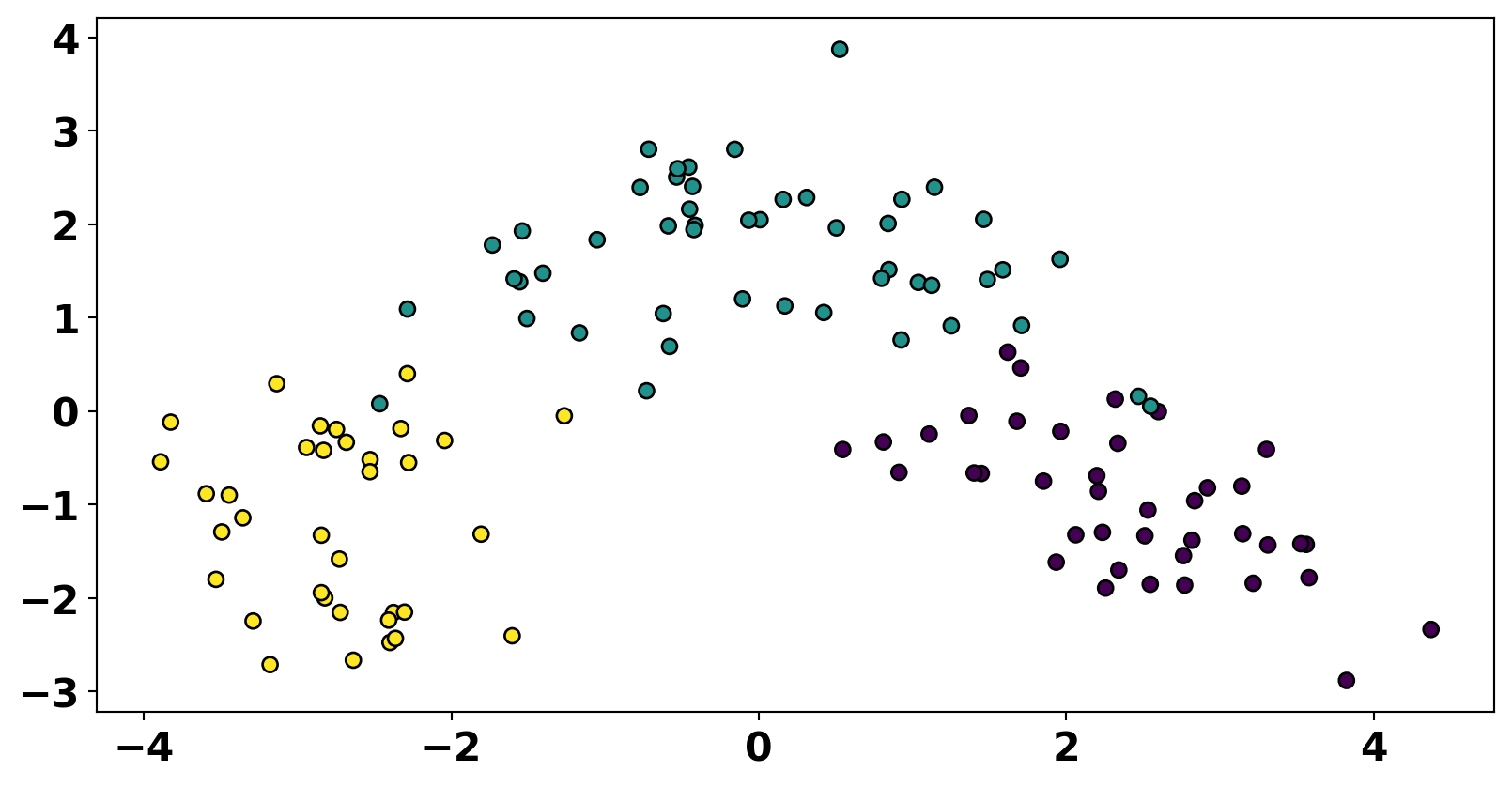
disp = DecisionBoundaryDisplay.from_estimator(
model, X_train_pca, response_method="predict", cmap=plt.cm.viridis, alpha=0.5, xlabel='PC1', ylabel='PC2'
)
disp.ax_.scatter(X_train_pca[:, 0], X_train_pca[:,1], c=y_train, cmap='viridis', edgecolor='k');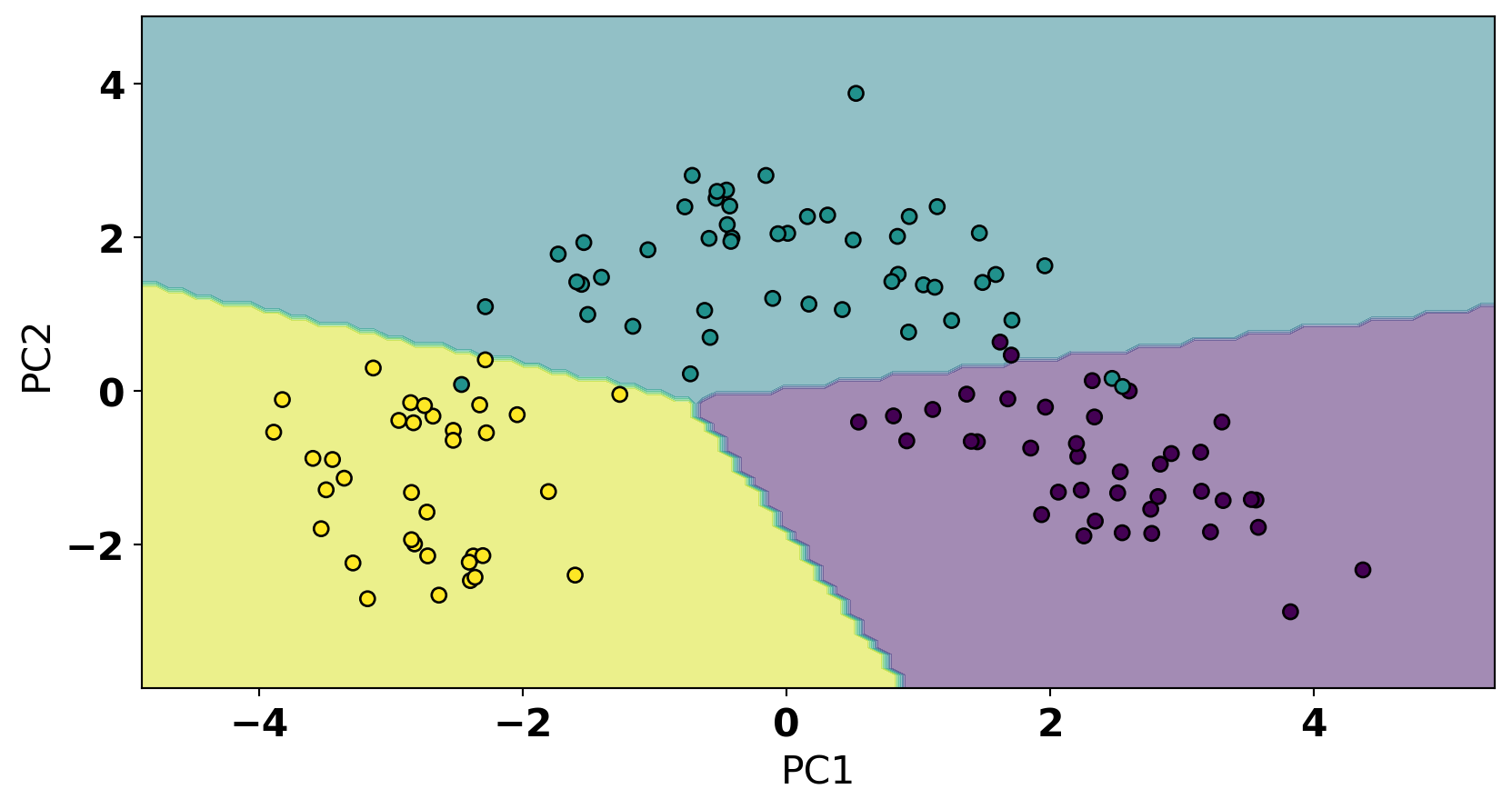
from sklearn.datasets import load_digits
mnist = load_digits()
X = mnist.data
y = mnist.target
images = mnist.images
fig, axes = plt.subplots(2, 10, figsize=(16, 6))
for i in range(20):
axes[i//10, i %10].imshow(images[i], cmap='gray');
axes[i//10, i %10].axis('off')
axes[i//10, i %10].set_title(f"target: {y[i]}")
plt.tight_layout()


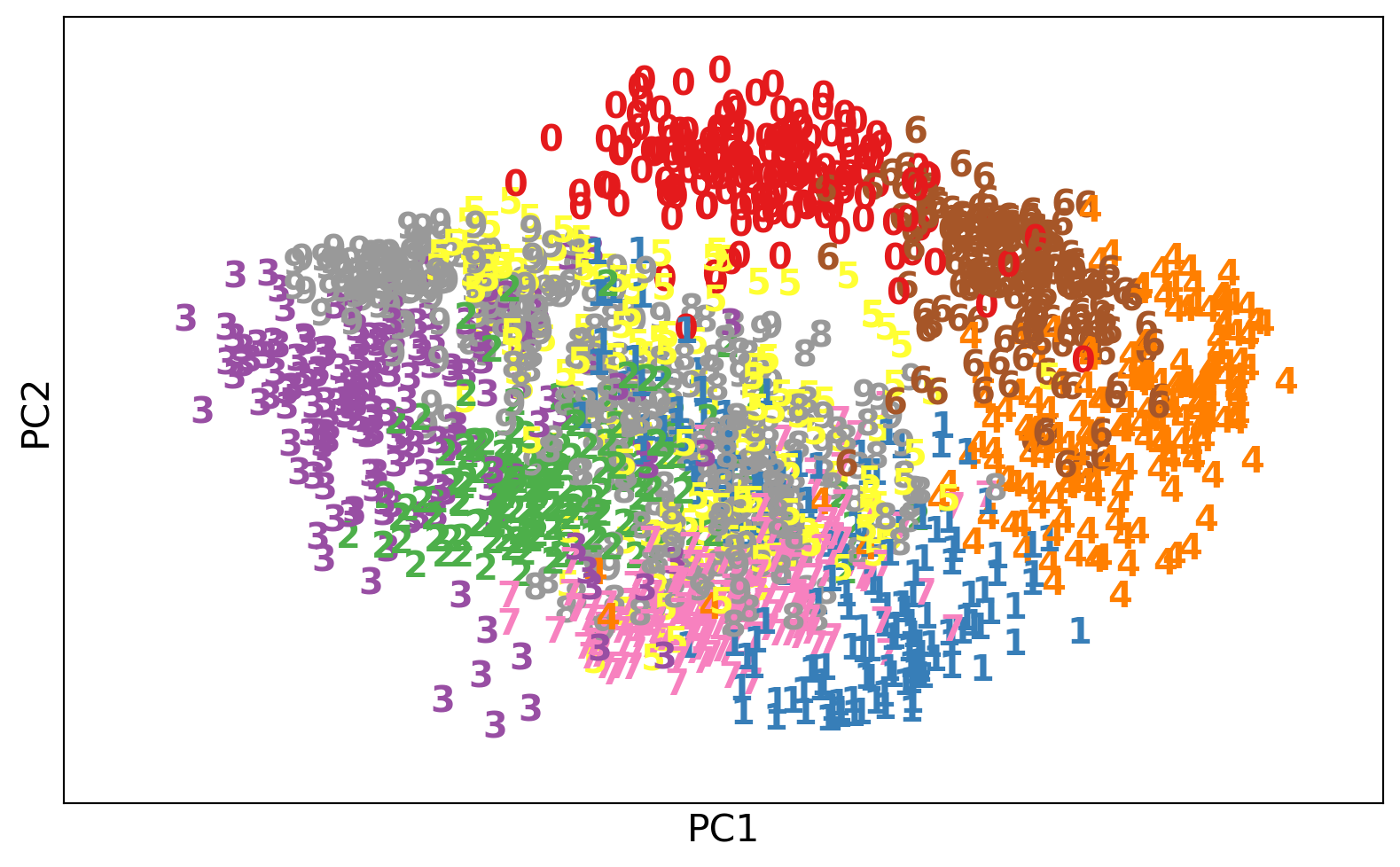
pca = PCA(n_components=64)
pca_data = pca.fit_transform(X)
percentage_var_explained = pca.explained_variance_ / np.sum(pca.explained_variance_)
cum_var_explained = np.cumsum(percentage_var_explained) * 100
plt.plot(range(1,65), cum_var_explained, linewidth=2)
plt.xlabel("Number of Components")
plt.ylabel("Cumulative Variance Explained");
plt.xticks(np.arange(0, 64, 4));
plt.ylim(0,100);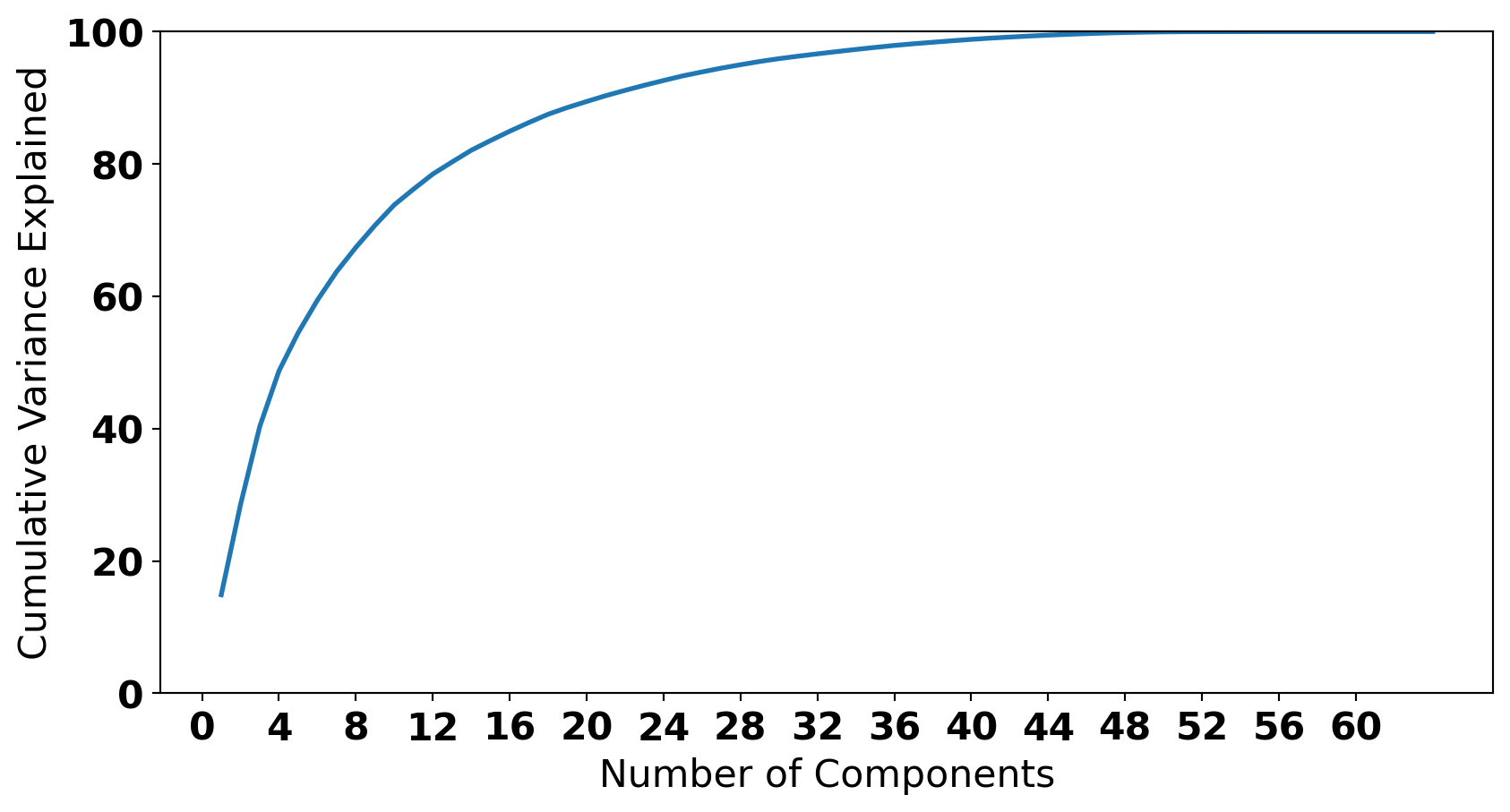


![]()