flowchart LR
A[Stats and Prob] --> B[Descriptive Statistics]
A --> C[Distribtuions]
A --> D[Population Inference]
E[Data Exploration] --> F[Plotting]
E --> G[Dataframes]
E --> H[Exploratory Data Analysis]
CISC482 - Lecture17
Supervised Learning - KNN
Exam Results
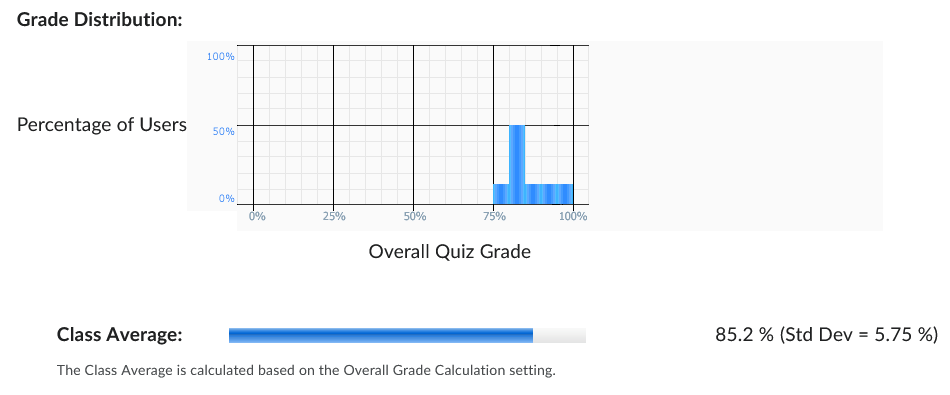
- Curve: +3 Bonus Points (3 questions, 6% bump)
- Average: 85%
Top Difficult Questions - #1
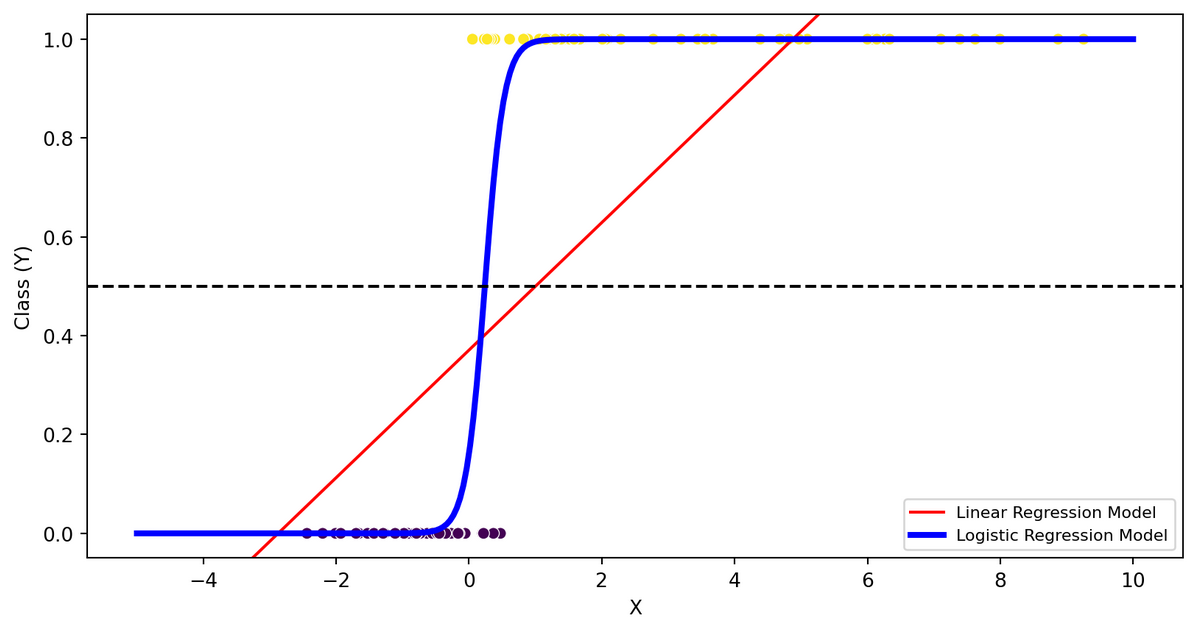
- Linear model has higher precision
- Linear model has worse recall
- Linear model has more FP
- Linear model has more FN
FN, TP, TN, FP
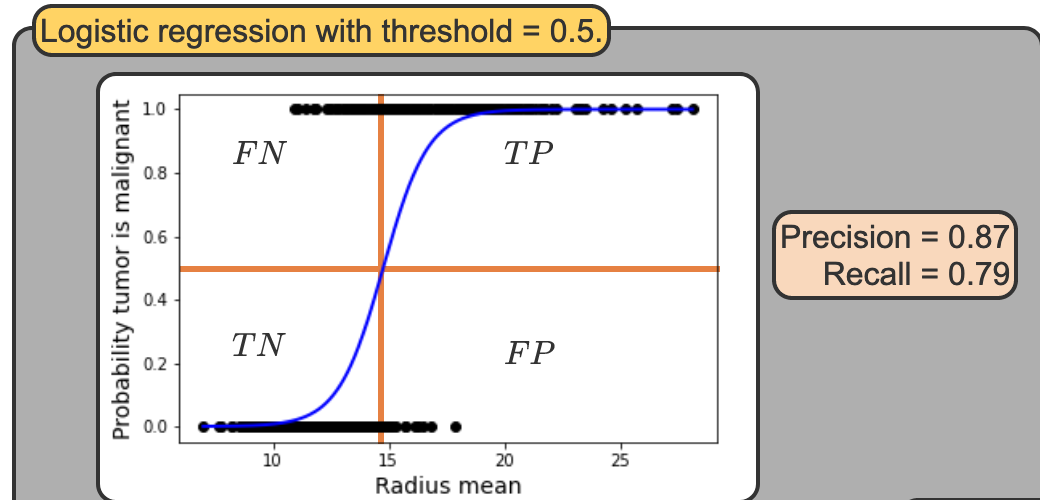
Top Difficult Questions - #3
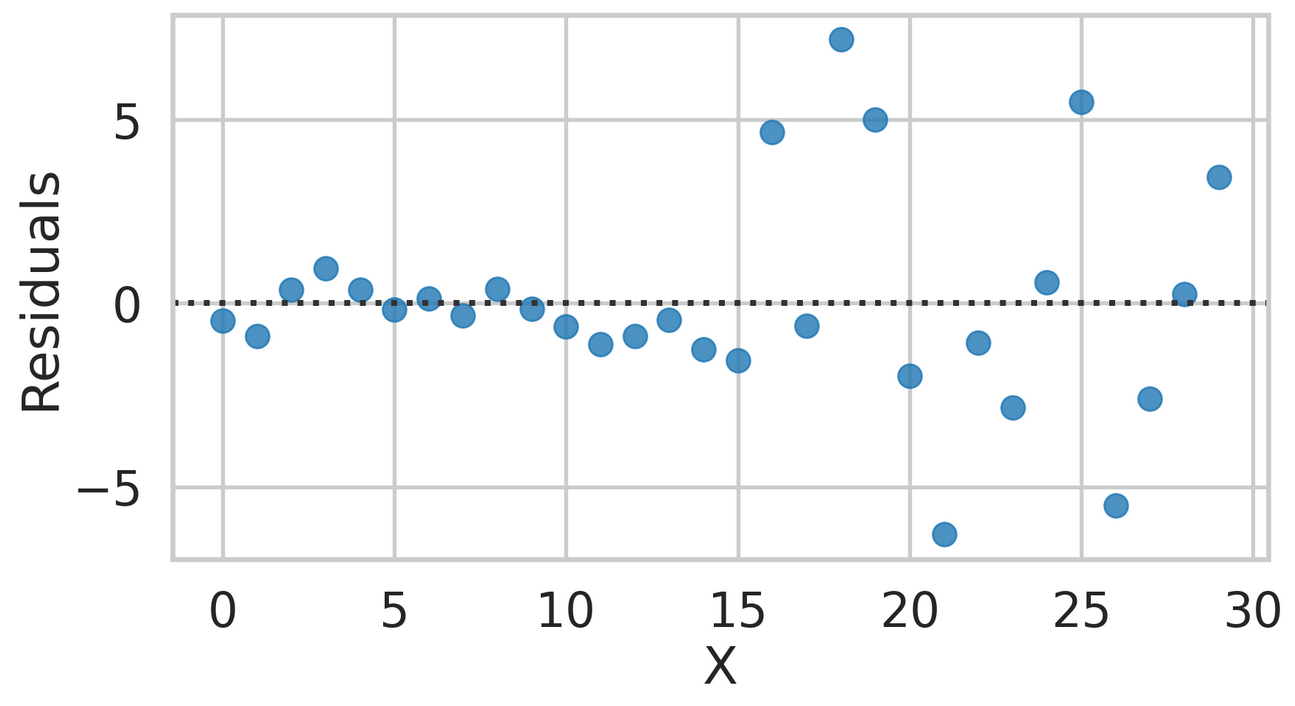
- Please explain if the assumptions of Linear Regression are met or not.
- You must discuss at least 3 of the assumptions and clearly explain if each assumption is met from looking at the graph.
Top Difficult Questions - #4
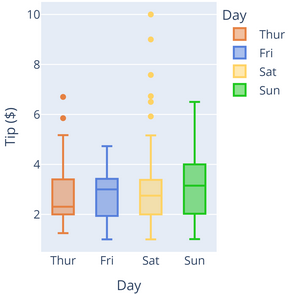
- Which day had the largest tip?
Example Regression Problem
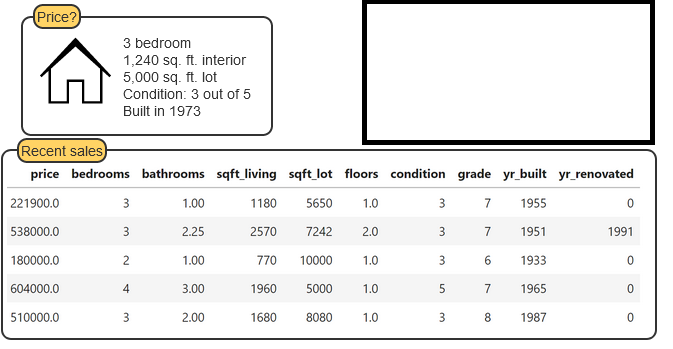
Example Classification Problem

Motivation
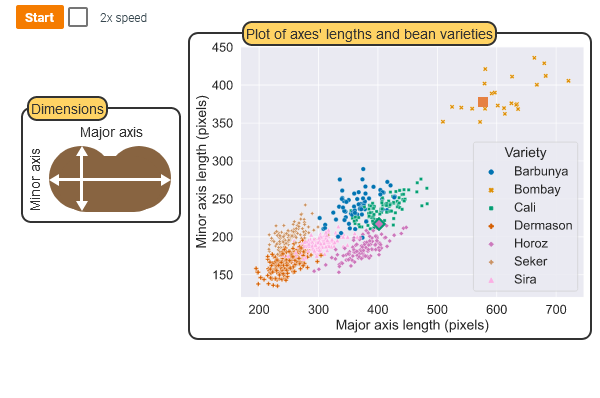
Example
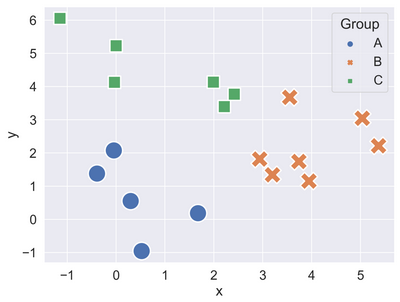
- (4, 2.5)
- (0, 4)
- (2, 1)
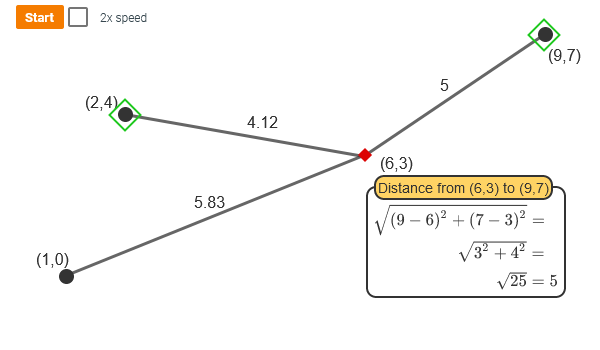
Finding your nearest neighbors
- How do determine how close a point is form the another (metric)
- distance(x,y) = \(\sqrt{(x_1 - y_1)^2 + (x_2 - y_2)^2 + ... + (x_p - y_p)^2 }\)
![Distance Calculation]()
Using KNN for Classification
Example - Data
Code
X, y = make_blobs(n_samples=100, centers=2, cluster_std=1.5, n_features=2,
random_state=0)
c_names = ["Class 0", "Class 1"]
fig, ax = plt.subplots(nrows=1, ncols=1)
scatter = ax.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis');
ax.legend(handles=scatter.legend_elements()[0],
labels=c_names,
title="Class")<matplotlib.legend.Legend at 0x7f12d8dd24d0>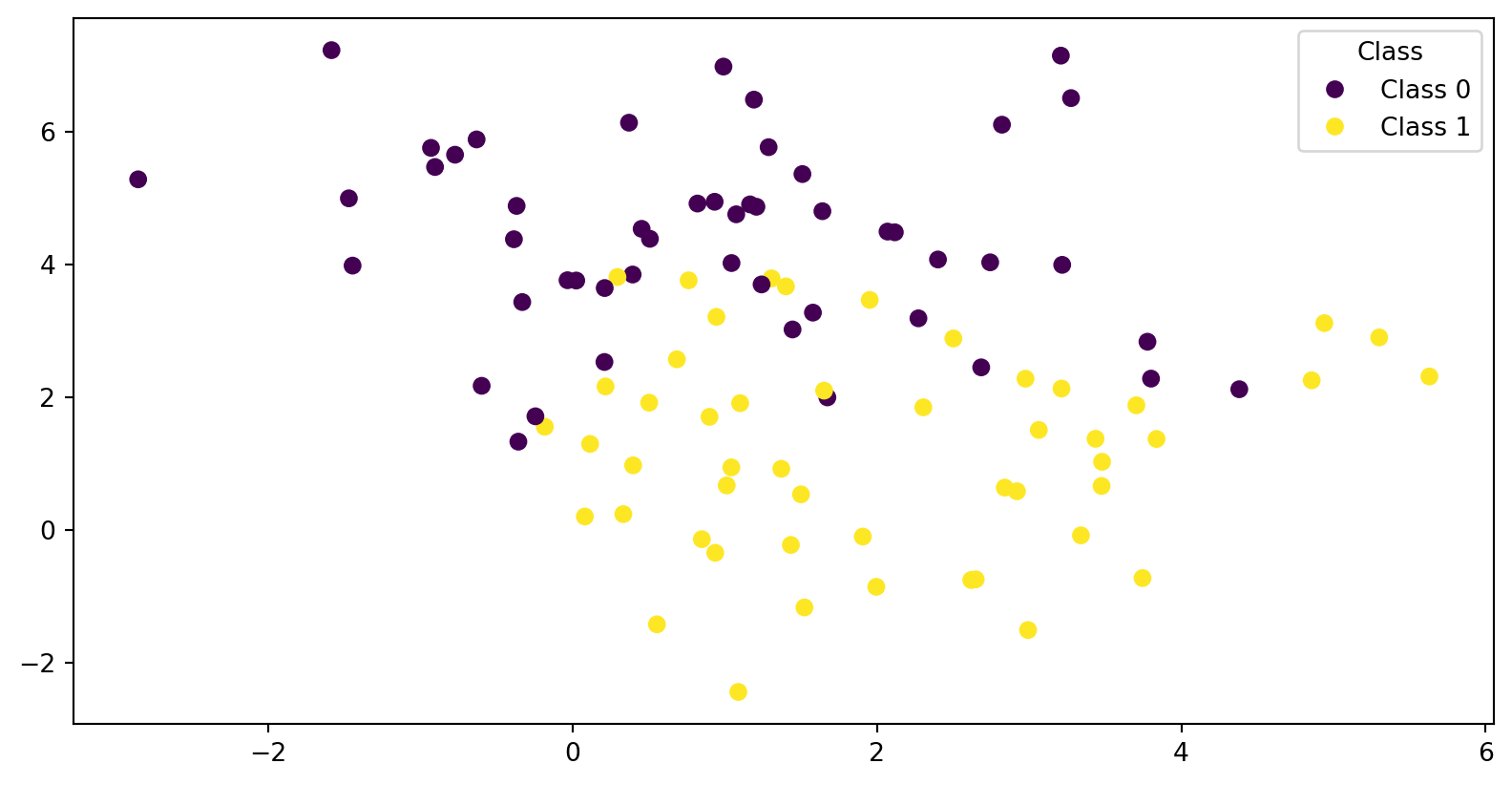
Split into Train and Test
Code
from sklearn.model_selection import train_test_split
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=0)
# Plot data
fig, ax = plt.subplots(nrows=1, ncols=2)
data = [(X_train, y_train, 'Train Set'), (X_test, y_test, 'Test Set')]
for (X, y, title), ax_ in zip(data, ax):
scatter = ax_.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis')
ax_.set_title(title)
ax_.set_xlabel("X0")
ax_.set_ylabel("X1")
ax_.legend(handles=scatter.legend_elements()[0],
labels=c_names,
title="Class")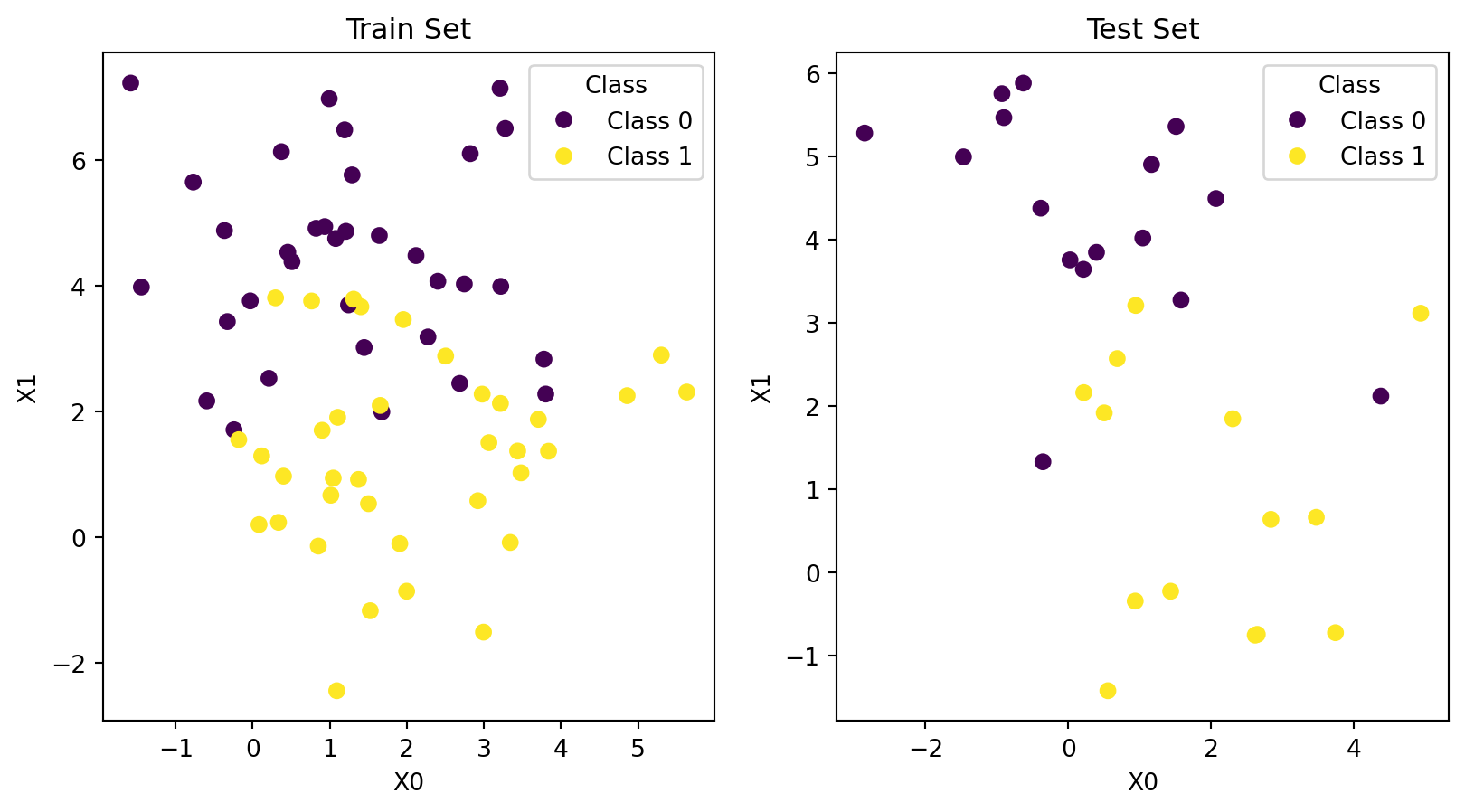
Test Model
Code
# Make predictions
predictions = model.predict(X_test)
# Plot data
fig, ax = plt.subplots(nrows=1, ncols=2)
data = [(X_test, y_test, 'Test Set (Ground Truth)'), (X_test, predictions, 'Test Set Predicted')]
for (X, y, title), ax_ in zip(data, ax):
scatter = ax_.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis')
ax_.set_title(title)
ax_.set_xlabel("X0")
ax_.set_ylabel("X1")
ax_.legend(handles=scatter.legend_elements()[0],
labels=c_names,
title="Class")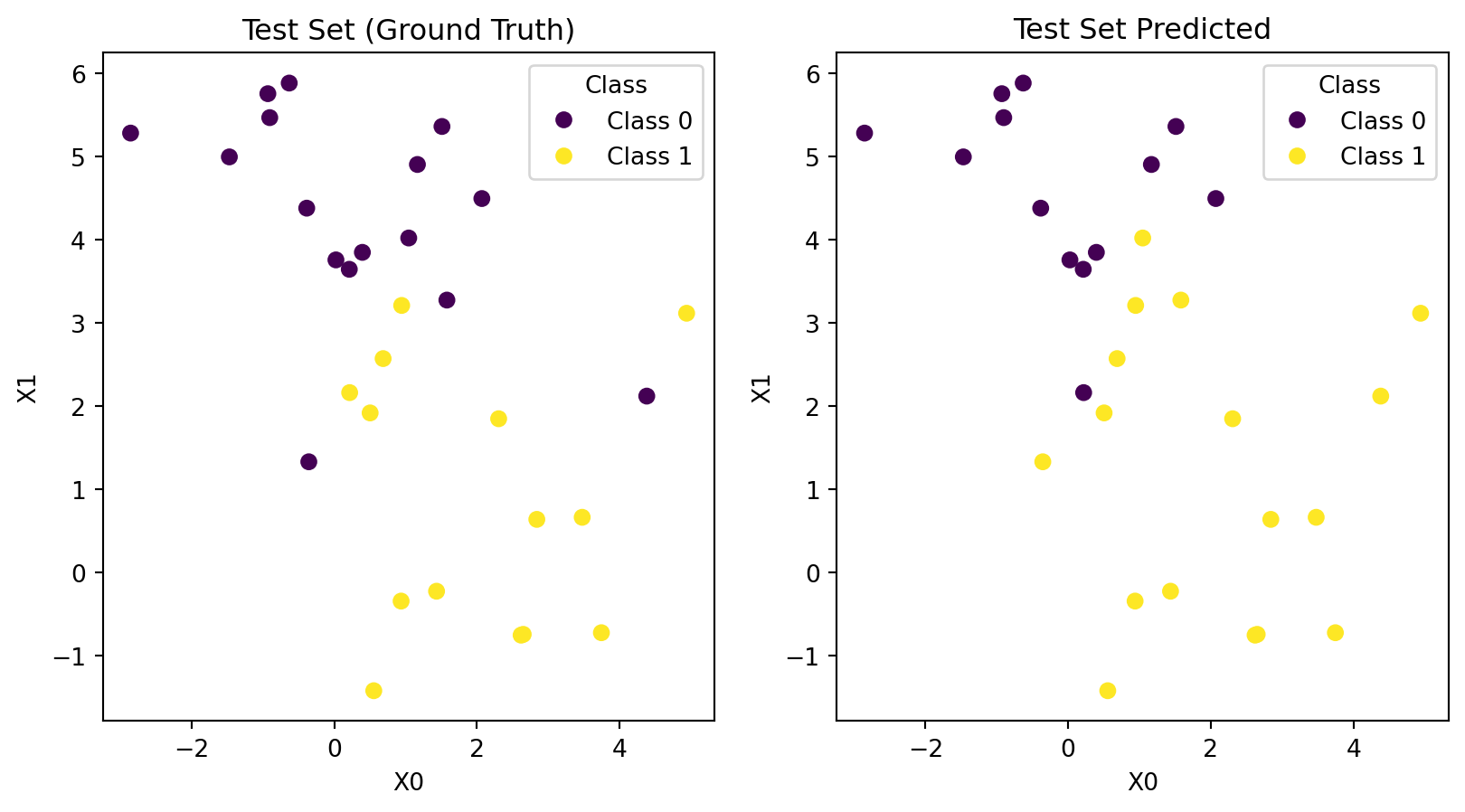
Confusion Matrix, Plot
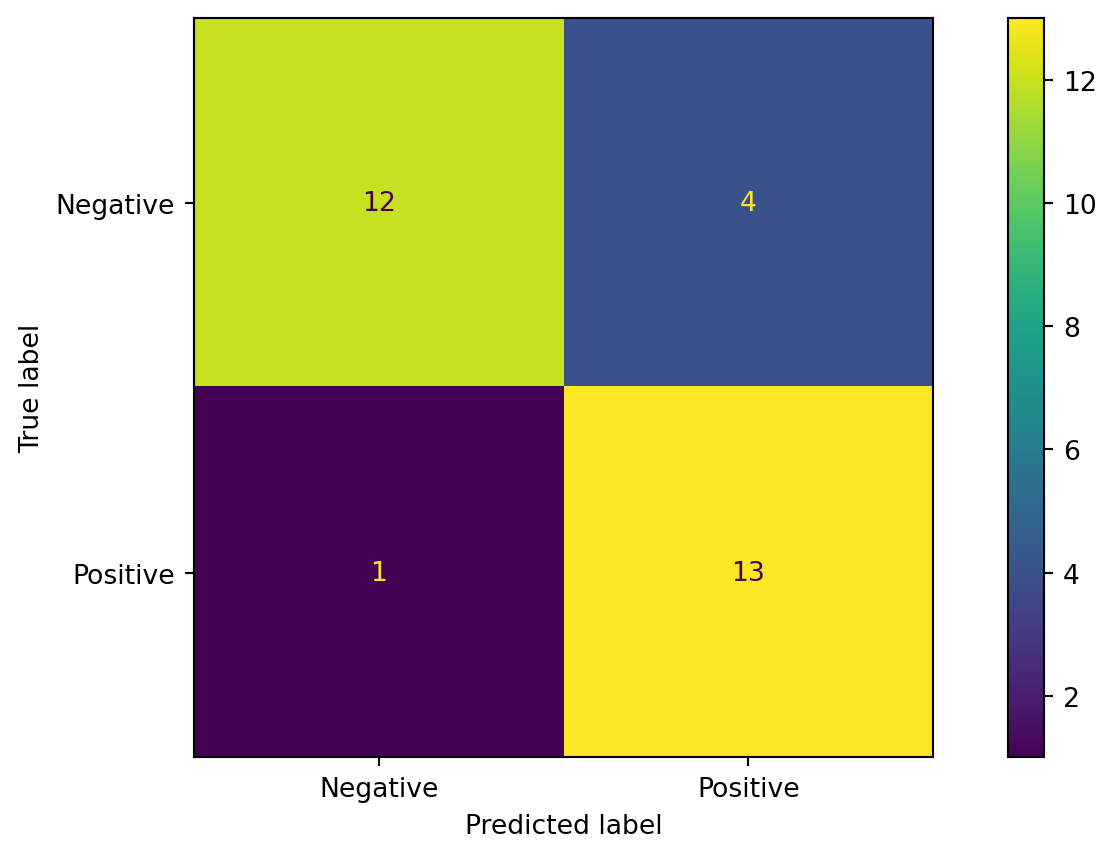
Classification Report
Code
precision recall f1-score support
Negative 0.92 0.75 0.83 16
Postive 0.76 0.93 0.84 14
accuracy 0.83 30
macro avg 0.84 0.84 0.83 30
weighted avg 0.85 0.83 0.83 30