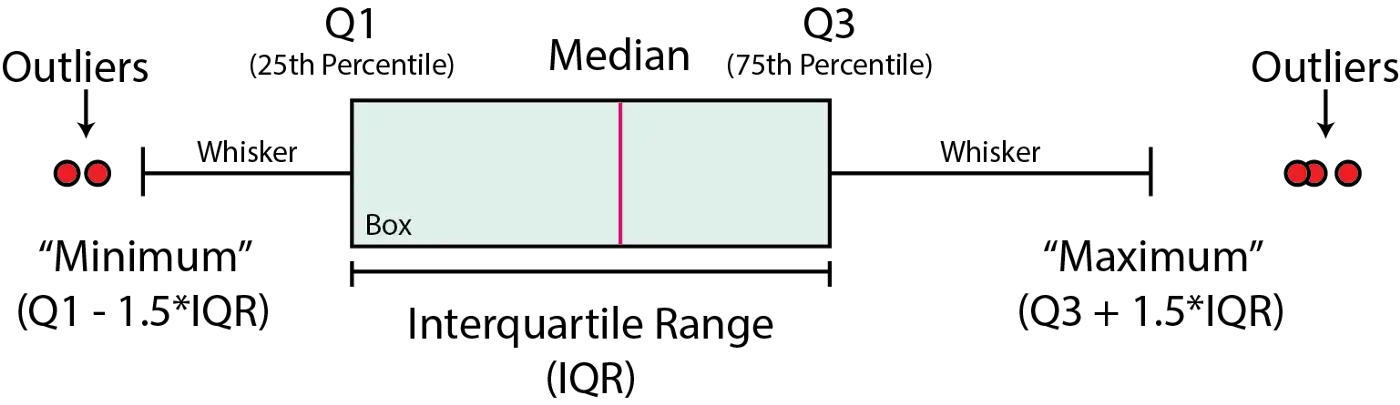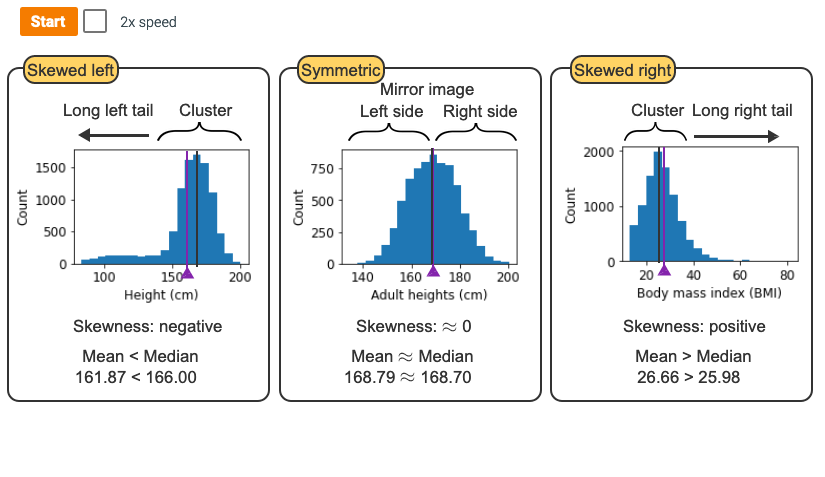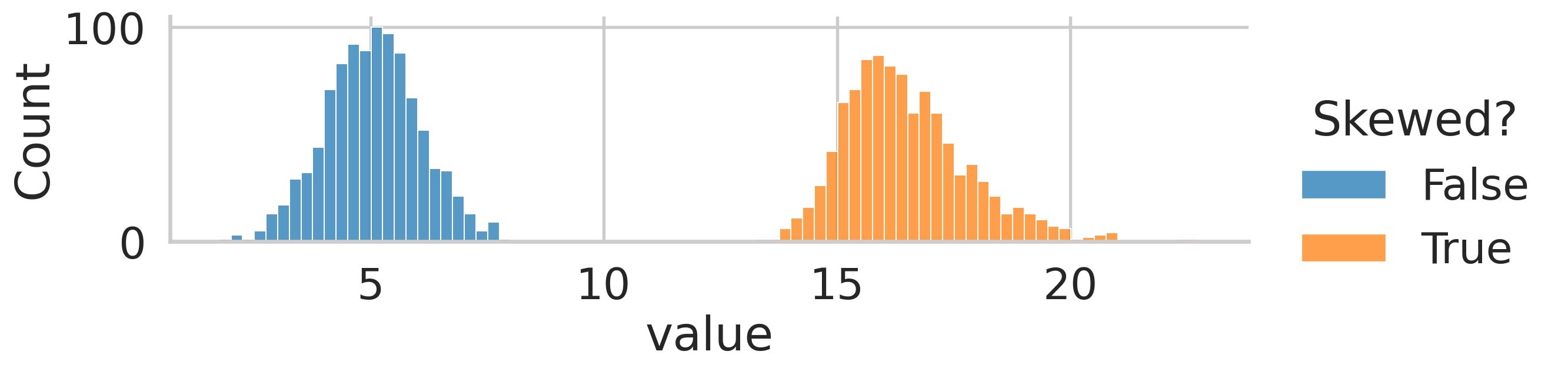
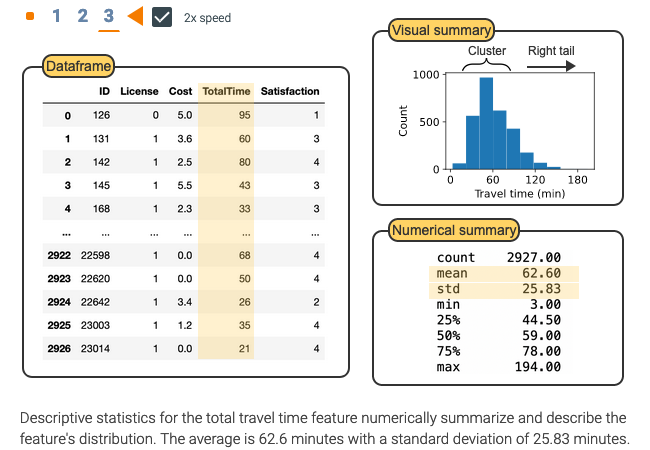

heights = [5.5, 5.7, 5.8, 5.9]
avg_height = sum(heights) / len(heights)
print(f"Average Height: {avg_height:.2f}")Average Height: 5.72Statistics
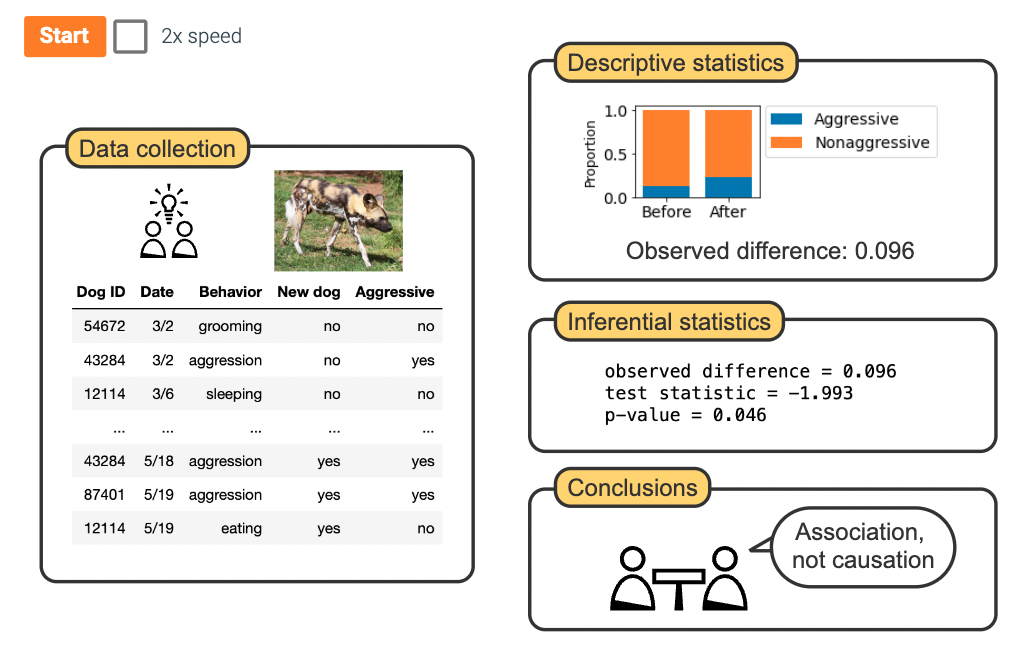

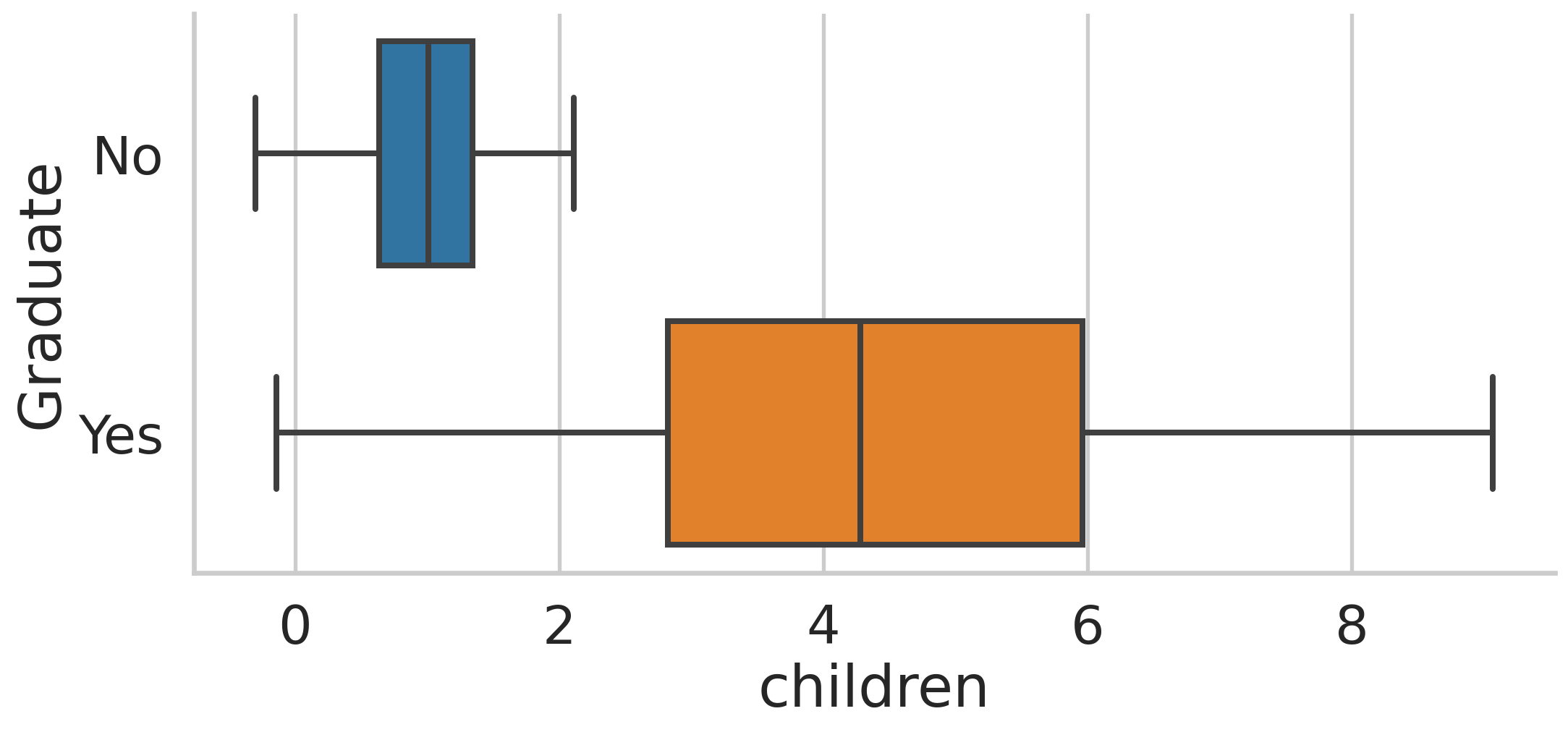
Advanced statistics -> I recommend using the library scipy. This library is built on top of numpy but has more functionality.
DescribeResult(nobs=1000, minmax=(1.7616568032476234, 7.787361447950662), mean=5.053665979218166, variance=1.0126662448100565, skewness=-0.0026145821525120016, kurtosis=-0.06654059199852824)